
Modelverse Dev
Initiative
A collaborative research ecosystem pioneering decentralized intelligence and cost-effective AGI development.
Our Evolution Roadmap
From compute efficiency to the ultimate goal of Artificial General Intelligence, we are architecting the future of decentralized systems.
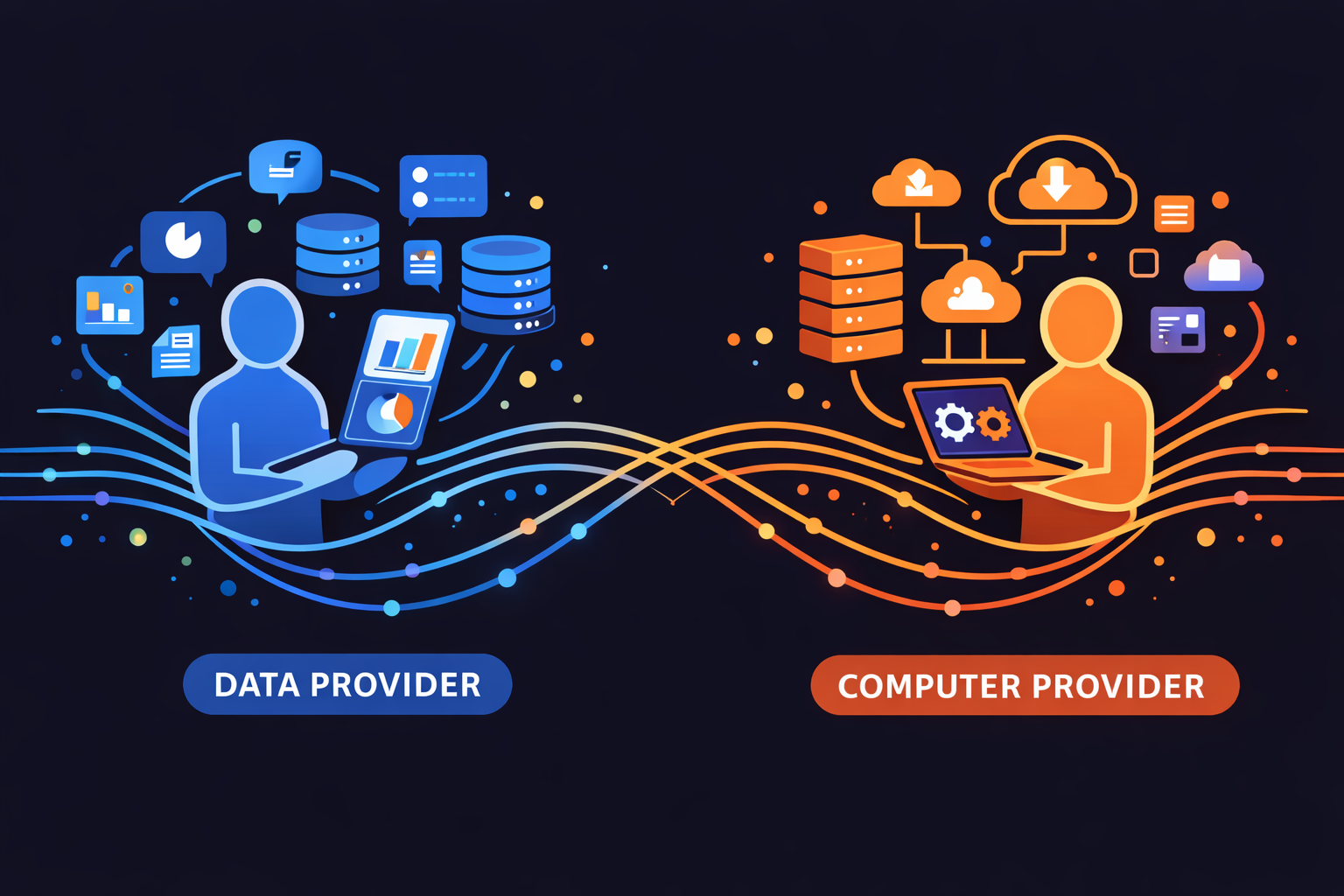
Compute × Data Matchmaking
for AI Training
We match compute and data—connecting data providers and compute providers (both centralized cloud and decentralized DePIN nodes) to help increase demand and give model creators cheaper compute + datasets, especially as scaling laws weaken.
Infrastructure Layer
Compute matchmaking margin across central cloud + DePIN nodes.
Data Sales
Sell model-training datasets to model creators.
Outcome
Higher provider demand + lower training cost for model builders.
The AI Bubble:
LLMs Are Hitting Their Hard Limits
A risk-hedging solution to the AI bubble crisis, driving cost reduction and efficiency through three core pillars.
1Economic Limits
- Inference costs 100–1000x higher than small models
- Users pay $150–300/month—not scalable
- GPU monopolies keep costs inflated
2Real Time Limits
- Too slow for real-time agents, trading, robotics
- Hallucinates on specialized tasks
- Scaling law returns are collapsing
3Ecosystem Limits
- One model cannot serve science & technology simultaneously
- LLMs fail on long-tail, domain-specific knowledge
- Centralized training misses 'niche-domain' expertise
A Public-Good Infrastructure for Intelligence
We are building an open ecosystem designed to democratize access, protect creator rights, and ensure transparent governance.
Universal AI Access
Democratizing intelligence through education and industry enablement
- Subsidized compute credits for academic & nonprofit research
- Sliding-scale access for students and emerging markets
- Standardized APIs for seamless industry integration
IP & Creator Rights
Attribution-first architecture with verifiable provenance
- Immutable on-chain registry for data provenance and licensing
- Granular opt-out mechanisms for content creators
- Fair revenue sharing rails for contributed datasets
Community Ownership
Governance by the people building the future
- Transparent council for protocol upgrades and policy decisions
- Open standards development for interoperability
- Shared ownership models for infrastructure providers
Decentralization is the
Only Path to AGI
Decentralized Intelligence is the ultimate frontier. As centralized systems hit the limits of marginal utility, a decentralized ecosystem provides a faster, more cost-effective, and highly specialized path to achieving true AGI across niche domains.
Centralized Intelligence can be cheaper, faster, and more timely, with better performance covering niche areas.
"Centralized scaling laws are reaching their peak; decentralized intelligence offers the performance and scalability required for the next leap in AGI."

Leadership
Fernando Jia
CEO
A seasoned professional with a rich background in tech and business. Guest lecturer at Carnegie Mellon University and University of Michigan. Ex-investor & fellow at Y Combinator, ex-McKinsey consultant, ex-IBD analyst at CITIC Securities. Alumnus of UC Berkeley's Center for Responsible Decentralized Intelligence.
Tianqin Li
Chief Scientist
PhD Researcher in CMU CS Department. Work with Tai Sing Lee (NeurIPS Neuroscience ex-Director), Zico Kolter (CMU AI Director in Computer Science, OpenAI Board member), Ruslan Salakhutdinov (VP Research @ Meta, ex-Apple AI Director, Student of AI's Founding Father, Geoffrey Hinton), and Louis-Philippe Morency (Multimodal AI pioneer professor). Tianqin is also a fellow at Y Combinator. Research focuses on AI models and human intelligence. NeurIPS 2023 Oral presentation (selective 1% of all submissions). Guest lecturer in multiple CMU AI courses.
Florence Li
Executive Team
Creative Technology Executive and Stanford CS master specializing in Machine Learning & Blockchain. Scaled MetaY's GPU DePIN platform. Introduced $10M+ in AI and Web3 investments. Frequent speaker at tech summits.
Advisory Board
Prof. Tai-Sing Lee
Director, Lee Lab for Biological & Machine Intelligence, CMU
Full Professor of Computer Science and Neuroscience at CMU. Dual PhDs from Harvard and MIT. Trained leaders at DeepMind, OpenAI, Google, and Berkeley, Yale etc. Recipient of McDonnell-Pew Young Investigator Award, NSF CAREER Award, and ICCV Helmholtz Prize.
Orion Parrott
Co-Founder & General Partner at Orange DAO
Bay Area entrepreneur and venture investor focused on early-stage Web3 and fintech. Y Combinator Summer '16 alumnus. Executive MBA from UC Berkeley's Haas School of Business.
Research Fellows
postdoc, UC Berkeley BAIR and RDI
postdoc, Stanford AI Lab
postdoc, CMU Robotics Institute
Ph.D., CMU Computational Biology
Ph.D., CMU Computer Science
Ph.D., Caltech Computational Science
Ph.D., Stanford Computational Science
Ph.D., MIT
postdoc, Harvard Medical School
postdoc, Caltech
Ph.D., Harvard CS
Ph.D., CMU Machine Learning & Public Policy
Ph.D., UM Bioinformatics
postdoc, Stanford University
Selected Publications from Research Fellows
Decentralized intelligence in gamefi: Embodied ai agents and the convergence of defi and virtual ecosystems.
Embodied ai agent for co-creation ecosystem: Elevating human-ai co-creation through emotion recognition and dynamic personality adaptation.
Surfgen: Adversarial 3d shape synthesis with explicit surface discriminators.
Conditional contrastive learning with kernel.
VSOLassoBag: a variable-selection oriented LASSO bagging algorithm for biomarker discovery in omic-based translational research.
Prototype memory and attention mechanisms for few shot image generation.
Emergence of Shape Bias in Convolutional Neural Networks through Activation Sparsity.
Learning weakly-supervised contrastive representations.
The EstroGene database reveals diverse temporal, context-dependent, and bidirectional estrogen receptor regulomes in breast cancer.
Integrating auxiliary information in self-supervised learning.
TPU-GAN: learning temporal coherence from dynamic point cloud sequences.
Using the SVM Method for Lung Adenocarcinoma Prognosis Based on Expression Level.
Structured Agent Distillation for Large Language Model.
Perceptual Inductive Bias Is What You Need Before Contrastive Learning.
ViT-Split: Unleashing the Power of Vision Foundation Models via Efficient Splitting Heads.
From Local Cues to Global Percepts: Emergent Gestalt Organization in Self-Supervised Vision Models.
Does resistance to style-transfer equal Global Shape Bias? Measuring network sensitivity to global shape configuration.
Learning More by Seeing Less: Line Drawing Pretraining for Efficient, Transferable, and Human-Aligned Vision.
Perceptual Inductive Bias Is What You Need Before Contrastive Learning.
Intelligence Cubed: A Decentralized Modelverse for Democratizing AI.
Does resistance to style-transfer equal Shape Bias? Evaluating shape bias by distorted shape.
The benefits of Incorporating Shape Priors in Contrastive Learning.
Manifold transform by recurrent cortical circuit enhances robust encoding of familiar stimuli.
Perceptual Inductive Bias Is What You Need Before Contrastive Learning.
SELF-ATTENTION-BASED CONTEXTUAL MODULATION IMPROVES NEURAL SYSTEM IDENTIFICATION.
Large-scale calcium imaging reveals a systematic V4 map for encoding natural scenes.
A large calcium-imaging dataset reveals a systematic V4 organization for natural scenes.
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces.
Learning to Reason without External Rewards.
Scalable Best-of-N Selection for Large Language Models via Self-Certainty.
Reward Shaping to Mitigate Reward Hacking in RLHF.
Improving LLM Safety Alignment with Dual-Objective Optimization.
Weak-to-Strong Jailbreaking on Large Language Models.
SoK: Watermarking for AI-Generated Content.
An Undetectable Watermark for Generative Image Models.
Permute-and-Flip: An Optimally Stable and Watermarkable Decoder for LLMs.
Invisible Image Watermarks Are Provably Removable Using Generative AI.
Provable Robust Watermarking for AI-Generated Text.
Protecting Language Generation Models via Invisible Watermarking.
Pre-trained Language Models Can be Fully Zero-Shot Learners.
Provably Confidential Language Modelling.
Crowd-robot interaction: Crowd-aware robot navigation with attention-based deep reinforcement learning.
TTT++: When Does Self-Supervised Test-Time Training Fail or Thrive?
Social nce: Contrastive learning of socially-aware motion representations.
On Pitfalls of Test-Time Adaptation.
Towards Robust and Adaptive Motion Forecasting: A Causal Representation Perspective.
Map-based deep imitation learning for obstacle avoidance.
Learning decoupled representations for human pose forecasting.
Causal Triplet: An Open Challenge for Intervention-centric Causal Representation Learning.
Bidirectional Decoding: Improving Action Chunking via Guided Test-Time Sampling.
Motion Style Transfer: Modular Low-Rank Adaptation for Deep Motion Forecasting.
Co-supervised learning: Improving weak-to-strong generalization with hierarchical mixture of experts.
Collaborative sampling in generative adversarial networks.
Forecast-PEFT: Parameter-efficient fine-tuning for pre-trained motion forecasting models.
Curating Demonstrations using Online Experience.
Sim-to-real causal transfer: A metric learning approach to causally-aware interaction representations.
Learning Long-Context Diffusion Policies via Past-Token Prediction.
Real-time distributed algorithms for nonconvex optimal power flow.
TAROT: Targeted Data Selection via Optimal Transport.
Translating natural language to planning goals with large-language models.
Toward general-purpose robots via foundation models: A survey and meta-analysis.
Embedding symbolic knowledge into deep networks.
Sigma: Siamese mamba network for multi-modal semantic segmentation.
Multi-task trust transfer for human–robot interaction.
Robot capability and intention in trust-based decisions across tasks.
Hiker-sgg: Hierarchical knowledge enhanced robust scene graph generation.
Dual prototype evolving for test-time generalization of vision-language models.
Embedding symbolic temporal knowledge into deep sequential models.
Shapegrasp: Zero-shot task-oriented grasping with large language models through geometric decomposition.
Self-correcting decoding with generative feedback for mitigating hallucinations in large vision-language models.
LogiCity: Advancing neuro-symbolic ai with abstract urban simulation.
Long-horizon dialogue understanding for role identification in the game of avalon with large language models.
VScan: Rethinking Visual Token Reduction for Efficient Large Vision-Language Models.
Enhancing vision-language few-shot adaptation with negative learning.
Let Me Help You! Neuro-Symbolic Short-Context Action Anticipation.
ONLY: One-Layer Intervention Sufficiently Mitigates Hallucinations in Large Vision-Language Models.
Semantically-regularized logic graph embeddings.
Revisiting nnu-net for iterative pseudo labeling and efficient sliding window inference.
The ninth NTIRE efficient super-resolution challenge report.
Self-supervised anomaly detection, staging and segmentation for retinal images.
Boosting dermatoscopic lesion segmentation via diffusion models with visual and textual prompts.
Distilling knowledge from topological representations for pathological complete response prediction.
An evaluation of u-net in renal structure segmentation.
ARCADE: Controllable Codon Design from Foundation Models via Activation Engineering.
CodonMoE: DNA Language Models for mRNA Analyses.
How Many Votes Is a Lie Worth? Measuring Strategyproofness through Resource Augmentation.
Truthful and Cost-Minimizing Model Routing in Graph-Based Agentic Workflows.
Incentive-Aware Multi-Fidelity Optimization for Generative Advertising in Large Language Models.
An Interpretable Automated Mechanism Design Framework with Large Language Models.
Efficient and Optimal Policy Gradient Algorithm for Corrupted Multi-armed Bandits.
Extending Myerson’s Optimal Auctions to Correlated Bidders via Neural Network Interpolation.
Cost-Efficient Information Aggregation in Hierarchical Information Structure.
Real-Time Recursive Routing in Payment Channel Network: A Bidding-based Design.
Low-Rank Modular Reinforcement Learning via Muscle Synergy.
Birds of a Feather Flock Together: A Close Look at Cooperation Emergence via Multi-Agent RL.
Surveying attitudinal alignment between large language models vs. humans towards 17 sustainable development goals.
Integrating multimodal information in large pretrained transformers.
A survey of large language models in medicine: Progress, application, and challenge.
Application of large language models in medicine.
Factorized multimodal transformer for multimodal sequential learning.
Driving analytics: Will it be OBDs or smartphones?
Guided diverse concept miner (GDCM): Uncovering relevant constructs for managerial insights from text.
Artificial Intelligence and user-generated data are transforming how firms come to understand customer needs.
Can Large Language Models Extract Customer Needs as well as Professional Analysts?
Apple at the Crossroads of AI: A Marbella AI Case Study.
Coreset Optimization by Memory Constraints, For Memory Constraints.
Clinical Decision System using Machine Learning and Deep Learning: a Survey.
Retrieving Knowledge of Molecular Regulatory Mechanisms from PubMed Titles via an Event Extraction Approach.
Recent Advances, Applications and Open Challenges in Machine Learning for Health: Reflections from Research Roundtables at ML4H 2022 Symposium.
The Measurement of Knowledge in Knowledge Graphs.
Demystify the Gravity Well in the Optimization Landscape (Student Abstract).
Learning More Effective Cell Representations Efficiently.
Towards Cross-Modal Causal Structure and Representation Learning.
A Machine Learning Approach to Lung Cancer Treatment Trajectory Analysis after Immunotherapy.
Serologic Profiling Using an Epstein-Barr Virus Mammalian Expression Library Identifies EBNA1 IgA as a Prediagnostic Marker for Nasopharyngeal Carcinoma.
Enhance ‘Similar’ Cell Identification Through Optimal Transport.
Sampling Through the Lens of Sequential Decision Making.
Retrieving Knowledge of Molecular Mechanisms from Literature Titles via an Event Extraction Approach.
COEM: Cross-Modal Embedding for MetaCell Identification.
Ranking Based Objectives with Wasserstein Distance.
Decomposable Sparse Tensor on Tensor Regression.
An Optimal Transport Approach to Deep Metric Learning (Student Abstract).
Online Review's Impact on Casino Revenue Management.
A Unified Model for Compressed Sensing MRI Across Undersampling Patterns.
Flow-Guided Neural Operator for Self-Supervised Learning on Time Series Data.
Open Vocabulary Monocular 3D Object Detection.
Pose-Aware Self-Supervised Learning with Viewpoint Trajectory Regularization.
Insight: A Multi-Modal Diagnostic Pipeline using LLMs for Ocular Surface Disease Diagnosis.
Multi-Modal Self-Supervised Learning for Surgical Feedback Effectiveness Assessment.
A Machine Learning Approach to Predicting Dry Eye-Related Signs, Symptoms and Diagnoses.
Artificial Intelligence Models Utilize Lifestyle Factors to Predict Dry Eye Related Outcomes.
Combinatorial Causal Bandits.
Peer Prediction for Learning Agents.
Causal Inference for Influence Propagation - Identifiability of the Independent Cascade Model.
Combinatorial Causal Bandits with Unknown Graph Skeleton.
Bond: Benchmarking unsupervised outlier node detection on static attributed graphs.
Pinnsformer: A transformer-based framework for physics-informed neural networks.
Pygod: A python library for graph outlier detection.
Beyond single-turn: A survey on multi-turn interactions with large language models.
Hyperparameter sensitivity in deep outlier detection: Analysis and a scalable hyper-ensemble solution.
Combining machine learning models using combo library.
Improving and unifying discrete&continuous-time discrete denoising diffusion.
Pard: Permutation-invariant autoregressive diffusion for graph generation.
Benchmarking node outlier detection on graphs.
Metaood: Automatic selection of ood detection models.
SUOD: toward scalable unsupervised outlier detection.
Fast unsupervised deep outlier model selection with hypernetworks.
From Detection to Action: a Human-in-the-loop Toolkit for Anomaly Reasoning and Management.
Firm or fickle? evaluating large language models consistency in sequential interactions.
DELPHYNE: A Pre-Trained Model for General and Financial Time Series.
SUOD: Toward Scalable Unsupervised Outlier Detection.
Physics informed machine learning with misspecified priors:an analysis of turning operation in lathe machines.
Hierarchical Token Prepending: Enhancing Information Flow in Decoder-based LLM Embeddings.
From Zero to Hero: Advancing Zero-Shot Foundation Models for Tabular Outlier Detection.
Threshold Differential Attention for Sink-Free, Ultra-Sparse, and Non-Dispersive Language Modeling.
Incremental Learning and Self-Attention Mechanisms Improve Neural System Identification.
A Large Dataset of Macaque V1 Responses to Natural Images Revealed Complexity in V1 Neural Codes.
Seeing is Believing: Belief-Space Planning with Foundation Models as Uncertainty Estimators.
Practice Makes Perfect: Planning to Learn Skill Parameter Policies.
E(2)-Equivariant Graph Planning for Navigation.
Integrating Symmetry into Differentiable Planning with Steerable Convolutions.
Scaling up and Stabilizing Differentiable Planning with Implicit Differentiation.
Toward Compositional Generalization in Object-Oriented World Modeling.
Deep Imitation Learning for Bimanual Robotic Manipulation.